Why a Purple Dot Appeared in My Mac’s Menu Bar During VLC Playback and How I Fixed It
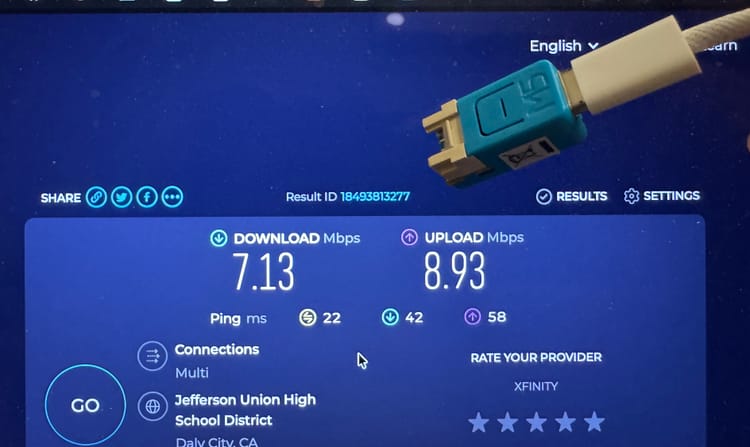
While watching a full-screen video in VLC on my Mac, I noticed a small purple dot appear in the menu bar—something I’d never seen before. It was distracting, so I set out to disable it.
Read More »